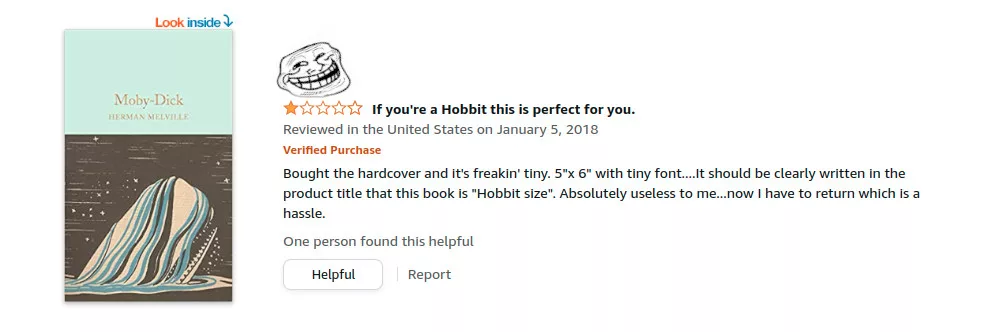
Pssst… over here… In the world of e-commerce, user reviews play a crucial role in influencing other people’s purchasing decisions. Besides that, we can harness this data to possibly train some neural network to classify reviews or even create pseudo reviews for a product. Using tools like Playwright and .NET Core, we can create a web scraper to collect these review data. In this blog post, I’ll show how to extract data from user reviews of books on Amazon.com.
Setting Up Your Environment
Before diving into the procedure, make sure you have .NET Core 6 SDK installed. You can download it from the official .NET website (I’m using Ubuntu Linux. If you are too, check the instructions here). After that, create a new C# console application project using your favorite IDE or by using the command line. I’ll use Visual Studio Code and the .NET command line tool.
mkdir AmazonScraper && cd AmazonScraper && dotnet new console --use-program-mainThis command will create a directory called AmazonScraper, cd into it and create a new .NET console application with the old program style (with the main method).
Installing Playwright
Playwright is an automation library like Selenum or Puppeteer that allows you to control web browsers programmatically. You can install the Playwright NuGet package using the following command in your project directory:
dotnet add package Microsoft.PlaywrightThis will install Playwright and its dependencies into your project. You can run Playwright with Chrome/Chromium or Firefox browser that you have installed on your system but it is also possible to install an “embedded” browser to ship it with your program. If it rings a bell, check how to install it here.
First Test, Navigate to Amazon.com
This program can be divided into two main functions: navigation and exporting data. As you may have guessed, the Navigation function navigates through pages and collects all data needed into a Review list. Also, this method saves the current state of the execution. The Export method does precisely that, it exports data as a JSON file.
You may also like




As mentioned before, I’m using the system-installed Chromium browser just by defining the ExecutablePath property of BrowserTypeLaunchOptions and passing it to the method LaunchAsync. It is worth mentioning that if you want to run the browser without rendering the main window, you have to set Headless = true (or by not defining the Headless property, once Headless = true is the default option):
namespace AmazonScraper;
using Microsoft.Playwright;
using System.Threading.Tasks;
public class Program {
public static async Task Navigate() {
using var playwright = await Playwright.CreateAsync();
await using var browser = await playwright.Chromium.LaunchAsync(
/*
this is important if you did not installed the "embedded"
browser. here I'am pointing the installed location of
chromium
*/
new BrowserTypeLaunchOptions()
{
/*
Headless = true if you want to run the browser
without rendring the main window
*/
Headless = false,
/*
system browser executable path
*/
ExecutablePath = "/snap/bin/chromium"
}
);
var page = await browser.NewPageAsync();
await page.GotoAsync("https://www.amazon.com.br/s?k=livros");
}
public static async Task Export() {
}
public static async Task Main(string[] args) {
await Navigate();
await Export();
}
}If you run this code, you should see a browser window and it will navigate automatically to the Amazon books page.
The goal is to scrape as many reviews as possible so I built an automatic navigation to recognize all the book elements in the root category, and then navigate to its review page.
Playwright provides a test generator that can generate C# code while you navigate manually through the site. The generator will recognize mouse clicks, the text you put on some textbox, read the XPath/Selector for each element and build all the jazz for you. You can find more about this kind of profanity here.
I went for the funny way and panned the XPath/Selectors for each element using the browser dev tools/console.
Review Object
This class has properties to identify the review.
public class Review
{
/// <summary>
/// review unique id
/// </summary>
public string Id { get; set; }
/// <summary>
/// product unique id
/// </summary>
public string ProductId { get; set; }
/// <summary>
/// review title
/// </summary>
public string Title { get; set; }
/// <summary>
/// review rating 1 to 5 stars
/// </summary>
public decimal Rating { get; set; }
/// <summary>
/// review body
/// </summary>
public string Comment { get; set; }
}Execution State and Configuration Object
I created the CurrentState object to give some flexibility, track how is going the process and add some failure handling. It has properties like current URL, next URL, max pages to navigate, etc.
public class CurrentState
{
/// <summary>
/// current product url
/// </summary>
public string ProductsUrl { get; set; }
/// <summary>
/// all product ids on the current page
/// </summary>
public List<string> ProductList { get; set; }
/// <summary>
/// the product id that is currently being processed
/// </summary>
public string CurrentProduct { get; set; }
/// <summary>
/// the next product page url
/// </summary>
public string NextUrl { get; set; }
/// <summary>
/// the maximum number of pages to be read
/// </summary>
public int MaxPages { get; set; }
/// <summary>
/// delay time in seconds between url navigations
/// </summary>
public int Delay { get; set; }
/// <summary>
/// the number of the page that is currently being processed
/// </summary>
public int CurrentPage { get; set; }
/// <summary>
/// the review list
/// </summary>
public List<Review> Reviews { get; set; }
/// <summary>
/// amazon store language (pt-BR, en-GB, en-US...)
/// </summary>
public string StoreLanguage { get; set; }
/// <summary>
/// amazon product review base url
/// </summary>
public string ProductReviewBaseUrl { get; set; }
/// <summary>
/// amazon product base url
/// </summary>
public string AmazonBaseUrl { get; set; }
}Also, I added some functions and variables to the file Program.cs to load and save the state.
Define a static variable to hold the name of the state:
private const string CurrentStateFileName = "current_state.json";Initialize the CurrentState object with default values.
private static CurrentState currentState = new()
{
MaxPages = 1,
AmazonBaseUrl = "https://www.amazon.com.br",
ProductReviewBaseUrl = "https://www.amazon.com.br/product-reviews",
ProductsUrl = "https://www.amazon.com.br/s?k=livros",
Delay = 5,
ProductList = new List<string>(),
Reviews = new List<Review>(),
StoreLanguage = "pt-BR"
};And write the functions to read and write the current state.
private async Task SaveCurrentState()
{
Console.WriteLine($"Save Current State: {currentState}");
await File.WriteAllTextAsync(CurrentStateFileName, JsonConvert.SerializeObject(currentState));
}
private async Task LoadCurrentState()
{
if (!File.Exists(CurrentStateFileName)) return;
Console.WriteLine($"Load Current State: {currentState}");
var tFile = await File.ReadAllTextAsync(CurrentStateFileName);
currentState = JsonConvert.DeserializeObject<CurrentState>(tFile);
}I used Newtonsoft Json to handle the serialization and deserialization of objects. Add it to the project by running:
dotnet add package Newtonsoft.JsonImproving Navigation
Once the book page is loaded, use Playwright methods like QuerySelectorAllAsync, QuerySelectorAsync, GetAttributeAsync and InnerTextAsync to interact with page elements and extract the relevant information.
Here is an example:
var productId = await productContainer.GetAttributeAsync("data-asin");This line of code is getting the product ID from a data attribute defined on an HTML tag, from a div in this particular case.
The navigation procedure is straightforward forward and it follows this diagram.
You may also like
At the start point “next URL” is the product URL defined via the current state JSON file or at the CurrentState object initialization, if there is no previous JSON file.
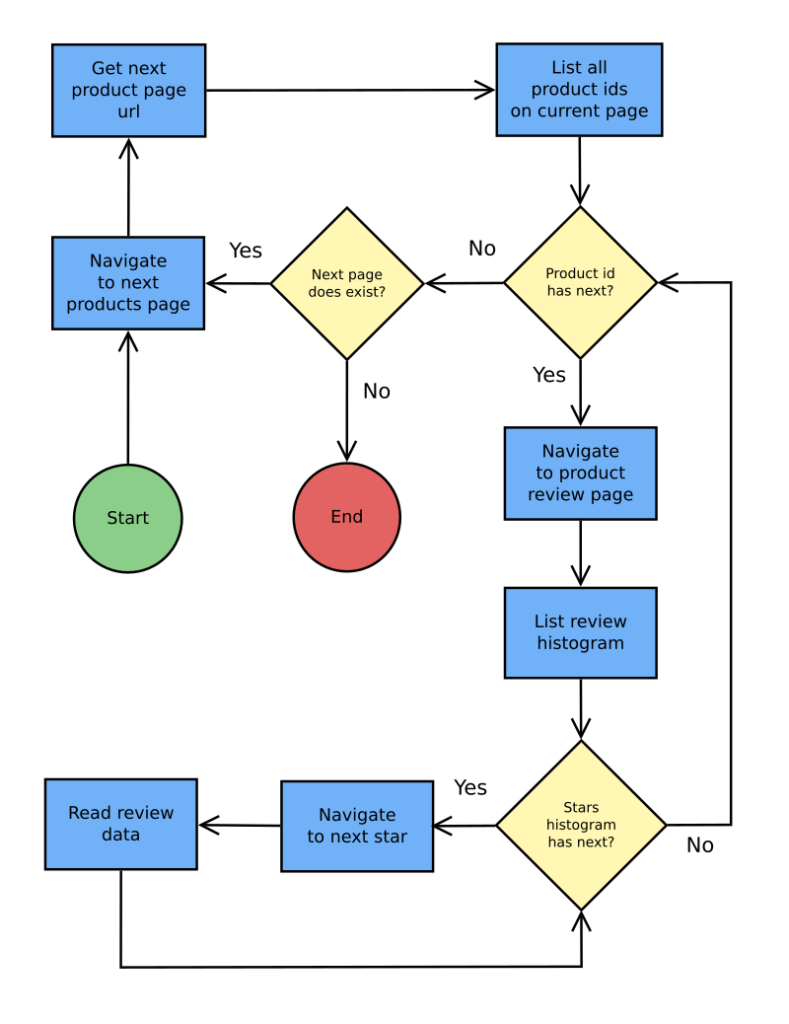
Is worth mentioning that each URL navigation is preceded by a delay with a bit of time drift, a small wait to simulate a random person navigating through products and reviews. I do not know if Amazon will block requests or ask for a captcha resolution but keep in mind this kind of trickery.
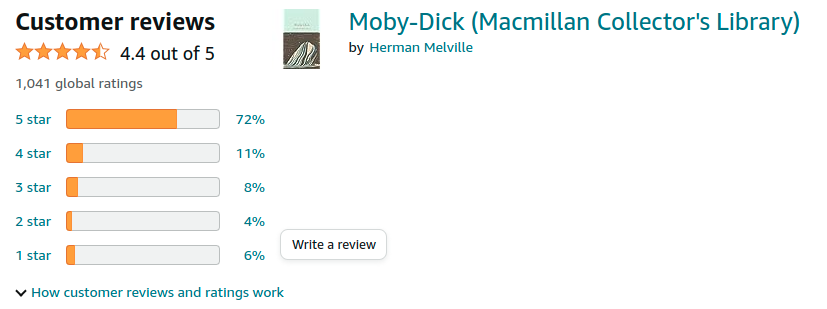
The histogram mentioned on the flow diagram is a star gauge widget that groups reviews by ratings. Like the one below.
Data Filtering and Exporting
At this point, you should have a pretty neat collection with hundreds of reviews yet, filtering and manipulating this data is made easy by using Linq.
First of all, let’s exclude duplicates if any.
var reviews = currentState.Reviews
.GroupBy(x => x.Id)
.Select(x => x.First()) //exclude duplicates
.OrderBy(x => x.Rating)
.ToList();Now let’s remove double spaces, new lines and some special characters that appeared somehow. Also, I changed the ratings according to my needs.
I’ll use this data to train an AI to categorize short sentences into sentiments that could be negative, neutral or positive. So to achieve that goal, I translated the ratings from a five-level (five stars) sentiment to a three-level one. That is, ratings less than three are now recognized as negative and with a value of zero, ratings equal to three are now recognized as neutral and with a value of 1 and the rest are recognized as positive and with a value of 2.
reviews.ForEach(r =>
{
if (Regex.IsMatch(r.Comment, @"\s{2,}"))
{
r.Comment = Regex.Replace(r.Comment, @"\s{2,}", " ", RegexOptions.Multiline);
}
if (Regex.IsMatch(r.Comment, @"\xA0"))
{
r.Comment = Regex.Replace(r.Comment, @"\xA0", "", RegexOptions.Multiline);
}
if (Regex.IsMatch(r.Comment, @"\n"))
{
r.Comment = Regex.Replace(r.Comment, @"\n+", "", RegexOptions.Multiline);
}
if(r.Rating < 3) r.Rating = 0;
if(r.Rating == 3) r.Rating = 1;
if(r.Rating > 3) r.Rating = 2;
});After that, I saved it to a JSON file with a sample list containing the same number of each one of the sentiments.
Conclusion
As you extract reviews, you can store them in a suitable data structure or save them to a database. Afterward, you can use the reviews to play with sentiment analysis or maybe gain insights into the book’s reception.
In conclusion, web scraping user reviews of books on Amazon opens up a world of possibilities for extracting valuable information. From setting up the environment to navigating web pages, extracting reviews, and analyzing the data, this guide has introduced you to the fundamentals of the process.
Note: Remember to adhere to ethical guidelines while scraping data from websites.
Get the sources: https://github.com/raffsalvetti/AmazonScraper
Until the next one!